
Kod genetyczny jest to stały i niezmienny szyfr, jakim posługuje się każda komórka, aby przetłumaczyć sekwencje nukleotydów na język białka. W niezmienionej formie występuje on u wszystkich żywych organizmów, a uniwersalność ta świadczy o ich wspólnym pochodzeniu. Wyjątkiem jest jednak DNA mitochondrialne, w którym niektóre zapisy mają inne znaczenie.
W łańcuchu DNA występują jedynie cztery zasady azotowe: Adenina (A), Guanina (G), Cytozyna (C) i Tymina (T) i tyle samo odpowiadających im nukleotydów. Kod genetyczny jest zatem czteroliterowy.
W strukturze białek może natomiast występować 20 różnych aminokwasów, a ich sekwencja, czyli kolejność w łańcuchu polipeptydowym, wyznacza strukturę i funkcje cząsteczki. Informacja genetyczna nie może być wobec tego zapisana za pomocą pojedynczych liter. Cztery zasady mogą tworzyć jedynie 16 kombinacji dwójkowych, co również nie stanowi optymalnej liczby. W związku z tym kod genetyczny posługuje się trzyliterowymi wyrazami, dającymi łącznie 64 różne warianty. Choć liczba ta znacznie przekracza ilość dostępnych aminokwasów, to pozwala jednak na zakodowanie każdego z nich unikatowym rodzajem zapisu.
Trójka kolejnych nukleotydów w cząsteczce DNA, czyli tak zwany triplet, jest symbolem informacyjnym i nosi nazwę kodonu. Kod genetyczny jest zatem trójkowy. Z 64 możliwych kodonów 61 koduje aminokwasy, natomiast 3 pozostałe są to kodony nonsensowe, czyli kodony stop oznaczające koniec translacji. Są to:
UAA – ochre,
UAG – amber,
UGA – opal.
Za pośrednictwem RNA triplety określają pozycje poszczególnych aminokwasów w syntetyzowanym łańcuchu polipeptydowym. Kolejność kodonów wyznacza kolejność aminokwasów. Kod jest więc kolinearny.
Jest on również jednoznaczny lub inaczej zdeterminowany, gdyż każda trójka nukleotydów wyznacza jeden, ściśle określony aminokwas.
Jeden aminokwas może być natomiast zapisany za pomocą kilku różnych kodonów. Tą cechę kodu określa się mianem zdegenerowania. Większość synonimów różni się między sobą ostatnią literą tripletu, co minimalizuje szkodliwe skutki mutacji, gdyż umożliwia występowanie zmian składu zasad DNA bez naruszania sekwencji aminokwasowej białka.
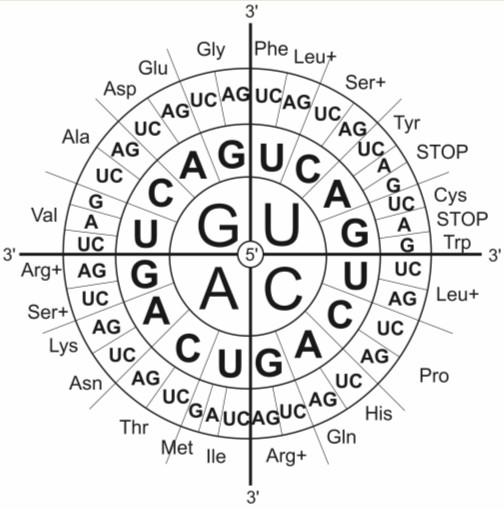
Rys. 1. Kod genetyczny. Każda trójka nukleotydów na mRNA wyznacza ściśle określony aminokwas
Ten sam nukleotyd nie jest składnikiem sąsiadujących trójek, ale wchodzi w skład jedynie jednego kodonu i dlatego mówi się, że kod jest niezachodzący.
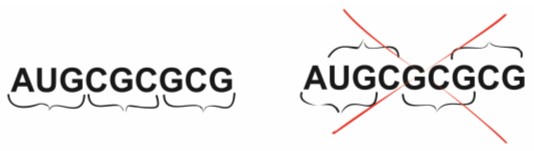
Rys. 2 Kod genetyczny jest niezachodzący
Jest on również bezprzecinkowy, ponieważ nie istnieją nukleotydy spełniające rolę znaków przystankowych i oddzielające od siebie poszczególne kodony.

Rys. 3. Kod genetyczny jest bezprzecinkowy
Autor: Anna Kurcek
Literatura:
• Lubert Stryer „Biochemia”, Wydawnictwo Naukowe PWN, Warszawa 2003;
• Ewa Pyłaka-Gutowska „Biologia. Vademecum Maturzysty” Wydanie siódme zmienione, Wydawnictwo „OŚWIATA”, Warszawa 2002.