
Autor: Anna Kurcek
Translacja jest procesem tłumaczenia (ang. translation) informacji z „języka” kwasów nukleinowych na „język” aminokwasów budujących cząsteczkę peptydu lub białka. Literami tworzącymi zakodowaną informację są cztery zasady azotowe (Adenina – A, Cytozyna – C, Guanina – G i Uracyl – U), w łańcuchu polipeptydowym występuje natomiast 20 różnych aminokwasów. Z tego powodu informacja genetyczna zapisana jest za pomocą uniwersalnego, trzyliterowego kodu, dającego 64 różne kombinacje. Oznacza to, że choć każda trójka nukleotydów (triplet lub inaczej kodon) wyznacza ściśle określony aminokwas (jednoznaczność, zdeterminowanie kodu), to może być on zapisany na kilka różnych sposobów (degeneracja kodu).
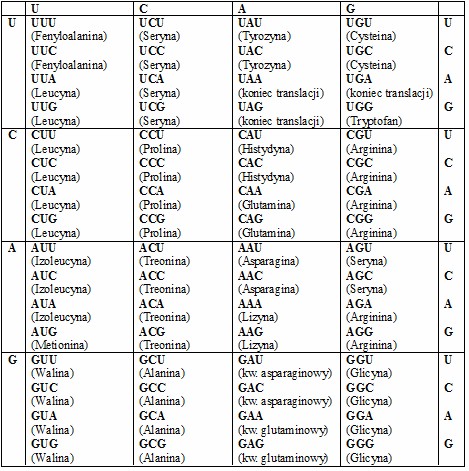
Rys. 1. Kod genetyczny
Lewy margines – pierwsza litera kodu genetycznego; góra – druga; prawy margines – trzecia. Pod każdą trójką nukleotydów podano nazwę kodowanego aminokwasu.
Zapis pozbawiony jest również znaków przystankowych, tzn. jest bezprzecinkowy i stanowi ciąg niezachodzących na siebie tripletów, których kolejność ustala sekwencję aminokwasów w budowanym białku. Tą cechę kodu nazywamy kolinearnością.
Translacja jest procesem bardzo skomplikowanym i wymaga skoordynowanego współdziałania ponad stu różnych rodzajów makrocząsteczek: rybosomów, tRNA, mRNA oraz wielu białek pomocniczych.
Rybosomy
Synteza białka przebiega na rybosomach, czyli dużych, składających się z dwóch podjednostek zespołach rybonukleoproteinowych. Mogą one jednocześnie odczytywać informację zakodowaną w dwóch kodonach matrycowego mRNA.
Przez wiele lat uważano, że główną funkcję podczas syntezy polipeptydów pełnią białka rybosomalne, natomiast rybosomalne RNA (rRNA) stanowi jedynie szkielet strukturalny. Obecnie wiadomo, że to nie prawda. Pozbawione białek rybosomy nadal mogą pełnić funkcje katalityczne podczas tworzenia się wiązań peptydowych w nowo syntetyzowanym łańcuchu aminokwasów.
Ze względu na wielkość rybosomy dzielimy na małe – o stałej sedymentacji (stałej Svedberga) – 70S (mniejsza podjednostka 30S, większa 50S). Nie są one związane z błonami komórkowymi, występują u Procaryota oraz u Eucaryota w plastydach i mitochondriach. Rybosomy duże, zwane także eukariotycznymi charakteryzują się stałą sedymentacji 80S (mniejsza podjednostka 40S, większa 60S) i zwykle związane są z błonami szorstkiego retikulum endoplazmatycznego. Rzadko występują w cytoplazmie jako wolne organelle. Liczba znajdujących się w komórce rybosomów zależy od jej aktywności metabolicznej.
mRNA – matrycowy, informacyjny lub inaczej przekaźnikowy RNA (z ang. messenger RNA)
Tworzony jest w procesie transkrypcji, jako cząsteczka komplementarna do nici wiodącej DNA. Jego funkcją jest przenoszenie do aparatu translacyjnego zakodowanej informacji genetycznej. Po połączeniu się z rybosomem pełni on zatem funkcję matrycy wyznaczającej kolejność aminokwasów w budowanym białku.
Translacja zachodzi w kierunku od końca 5’ do 3’.
tRNA – transportujący, transferowy RNA (ang. transfer RNA)
Cząsteczka ta zbudowana jest z 76- nukleotydowego, pojedynczego łańcucha przybierającego charakterystyczny kształt liścia koniczyny.
Występuje w różnych postaciach, które różnią się między sobą sekwencją nukleotydów. Mogą w nim występować również inne zasady azotowe, tzn. metylocytozyna, hydroksymetylocytozyna, pseudouracyl, dihydrouracyl.
Koniec 5’ łańcucha jest fosforylowany, natomiast 3’ zawiera wolną grupę hydroksylową łączącą się z grupą karboksylową odpowiedniego aminokwasu. Reakcja ta wymaga nakładu energii dostarczanej przez ATP i katalizowana jest przez enzym syntetezę aminoacylo-tRNA. Pośrodku każdej cząsteczki tRNA znajduje się tzw. pętla antykodonowa, determinująca rodzaj transportowanego aminokwasu. To właśnie zawarta w niej sekwencja (5’ – pirymidyna – pirymidyna – X –Y – Z – zmodyfikowana puryna – zmienna zasada – 3’) umożliwia odnalezienie właściwej cząsteczki przez specyficzną syntetazę.
Jest ona również odpowiedzialna za rozpoznawanie właściwego tripletu na łańcuchu mRNA – determinuje zatem przyłączanie właściwego aminokwasu do powstającego polipeptydu. Niektóre tRNA rozpoznają więcej niż jeden kodon. Dzieje się tak, ponieważ parowanie ostatniej zasady jest mniej specyficzne niż dwóch pozostałych nukleotydów. Regułę tę nazywamy zasadą tolerancji.
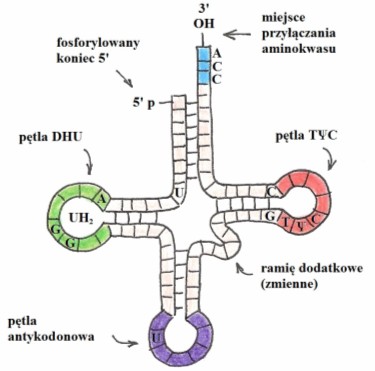
Rys. 2. Ogólny schemat budowy cząsteczki tRNA
Proces syntezy białka zachodzi w cytoplazmie. Można podzielić go na trzy etapy, których przebieg zasadniczo nie różni się u organizmów eukariotycznych i prokoriotycznych, jednak u tych ostatnich translacja jest sprzężona z zachodzącą w jądrze transkrypcją i rozpoczyna się jeszcze przed ukończeniem syntezy mRNA. Kilka rybosomów może wtedy „tłumaczyć” zapisaną na mRNA informację.
Inicjacja translacji – polega na połączeniu się nici mRNA z podjednostkami rybosomy. Razem tworzą one tzw. kompleks translacyjny, zwany również „maszyną translacyjną”. Kodonem inicjującym translację na mRNA jest sekwencja AUG (rzadziej GUG). Startowa trójka nukleotydów ustawiona jest w miejscu P (peptydylowym, czyli zajmowanym przez tRNA połączony z polipeptydem) na rybosomie. Do niej przyłącza się inicjatorowy aminoacylo – tRNA. Pierwszym aminokwasem nowo zsyntetyzowanego łańcucha jest zawsze metionina (u Eucaryota) lub jej pochodna – formylometionina (u Procaryota).
Elongacja translacji – etap ten rozpoczyna się, gdy pierwszy aminoacylo-tRNA zajmie miejsce A (aminoacylowe, czyli zajmowany przez tRNA połączony z aminokwasem) na rybosomie. Budowa przestrzenna kompleksu translacyjnego umożliwia zbliżenie się grupy karboksylowej pierwszego aminokwasu do grupy aminowej drugiego aminokwasu. Proces tworzenia wiązań peptydowych między nimi wymaga nakładu energii oraz obecności enzymów rybosomowych. Uwolniona od polipeptydu cząsteczka tRNA opuszcza miejsce P i wraca do cytoplazmy, gdzie ponownie połączy się z właściwym sobie aminokwasem. Rybosom natomiast przesuwa się wzdłuż matrycy mRNA i w ten sposób w miejscu A pojawia się kolejna wolna trójka nukleotydów.
Cząsteczki aminokwasów przyłączane są do końcowej grupy karboksylowej tworzonego polipeptydu – białko syntetyzowane jest zatem w kierunku od końca N do końca C. Dalsze cykle elongacyjne zachodzą według tego samego schematu.
Terminacja translacji – zakończenie syntezy łańcucha polipeptydowego wyznaczają tzw. kodony stop – (UAA, UAG, UGA). Nie są one rozpoznawane przez cząsteczki tRNA i dlatego zajmując miejsce A na rybosomie wstrzymują wydłużanie łańcucha. Powstałe białko uwalniane jest z kompleksu dzięki tzw. czynnikom uwalniającym (RF – ang. release factor) i ulega dalszej obróbce, podczas której przybiera właściwą sobie formę przestrzenną.
![]()
Rys. 3. Przebieg wydłużania łańcucha polipeptydowego
Literatura:
• Waldemar Lewiński, Jolanta Walkiewicz „BIOLOGIA 1 – podręcznik dla klasy pierwszej liceum ogólnokształcącego”, Wydawnictwo „OPERON” 1998;
• Wilhelm Grzesiak, Arkadiusz Marian Kawęcki „GENETYKA ZWIERZĄT – przewodnik do ćwiczeń”, Akademia Rolnicza w Szczecinie, Szczecin 1998;
• Lubert Stryer „Biochemia”, przekład zbiorowy pod redakcją Jacka Augustyniaka i Jana Michejdy z czwartego wydania amerykańskiego; Wydawnictwo Naukowe PWN, Warszawa 2003;
• Robert K. Murray, Daryl K. Granner, Peter A. Mayes, Victor W. Rodwell “Biochemia HArpera” Wydanie III, Redaktor naukowy tłumaczenia Franciszek Kokot; Wydawnictwo Lekarskie PZWL; Warszawa 1995;